International Conference on Recent Advances in Survey Sampling
ABSTRACTS
Non-parametric Rank Tests for independence in opinion surveys
Mayer Alvo, Philip Yu, K. Lam
Nonparametric rank tests for independence between two characteristics are commonly used in many social opinion surveys. When both characteristics are ordinal in nature, tests based on rank correlations such as those due to Spearman and Kendall are often used. The case where some ties exist has already been considered whereas Alvo and Cabilio (1995) have studied the case when there are missing values but no ties in the record. However, it frequently happens that the survey data may contain simultaneously many tied observations and/or many missing values. A naive approach is to simply discard the missing observations and then to make use of the rank correlations adjusted for ties. This approach would be less powerful as it does not fully utilize the information associated with the incomplete data set. In this article, we generalize Alvo and Cabilio's notion of distance between two rankings to incorporate tied and missing observations, and define new test statistics based on the Spearman and Kendall rank correlation coefficients. We determine the asymptotic distribution of the Spearman test statistic and compare its efficiency with the corresponding statistic based on the naive approach. The proposed test is then applied to a real data set collected from an opinion survey conducted in Hong Kong.
Regression Estimators for the 2001 Canadian Census
Mike Bankier, Statistics Canada
In the 2001 Canadian Census of Population, calibration or regression estimation was used to calculate a single set of household level weights to be used for all Census estimates based on a 1 in 5 national sample of more than two million households. Because many auxiliary variables were available, only a subset of them could be used. Otherwise, some of the weights would have been smaller than one or even negative. A forward selection procedure was used to discard auxiliary variables which caused weights to be smaller than zero or which caused a large condition number for the calibration weight matrix being inverted. Also, two calibration adjustments were done to achieve close agreement between auxiliary population counts and estimates for small areas. Prior to 2001, the projection Generalized Regression (GREG) Estimator was used and the weights were required to be greater than 0. For the 2001 Census, a switch was made to a pseudo-optimal regresssion estimator which kept more auxiliary variables while, at the same time, required that the weights be one or more.
Analysis Issues for Data from Complex
Surveys
David A. Binder and Georgia R. Roberts, Statistics Canada
Fitting models to data is a common practice in statistical applications.
The properties of the estimates obtained using "traditional" fitting
methods are generally well known under certain model assumptions. However, one
key implicit assumption is that the sample design used to collect the data is
not informative. We describe what this means when applied to complex survey
data and discuss methods of analysis that are valid whether or not the designs
are informative. Emphasis is placed on target parameters motivated from a model
and on the assumptions about what is random.
A Nonparametric Regression Smoother for Nonnegative Data
Yogendra P. Chaubey, Concordia University,
Pranab K. Sen, University of North Carolina
Xiaowen Zhou, Concordia University
Recently, there has been a lot of development in nonparametric regression using kernel method, local linear smoothing, splines and so on. Some of these methods seem to work well, however, there are no clear winners. Moreover, these methods are general purpose methods and there may be scope for better methods in specific situations. For example, when the observations are known to be nonnegative there is no reason to use a symmetric kernel, which may unnecessarily put mass over some negative values. Such situations are common in survival studies. Motivated by such problems, Chaubey and Sen (2001) provide an alternative method of smoothing the multivariate survival function and study its asymptotic properties along with that of the derived
probability density function. In this paper, we consider use of this estimator in proposing estimators of continuous functionals of the joint survival function. In this process we derive an alternative smooth estimator of the regression function E(Y|X) where X is a vector of p independent variables, assuming non-negative support for all variables. Properties of the derived estimator are theoretically and numerically investigated.
Empirical Likelihood Confidence
Intervals
for a Population Containing Many Zero Values
Jiahua Chen, University of Waterloo
If a population contains many zero values and the sample size is not very large,
the central limit
theorem based confidence intervals for the population mean may have poor coverage
prob-abilities. This problem is substantially reduced by constructing parametric
likelihood ratio intervals when an appropriate mixture model can be found. However,
in the context of
survey sampling, a general preference is to make minimal assumption about the
population.
We have therefore investigated the coverage properties of nonparametric empirical
likelihood
confidence intervals for the population mean. Under a variety of hypothetical
populations, the empirical likelihood intervals often outperformed parametric
likelihood intervals by having
larger lower bounds, or more balanced coverage rates. We have also used a real
data set to illustrate the empirical likelihood method.
This is joint work with Shun-Yi Chen and J.N.K. Rao.
Composite Estimation in Small Area Inference
Gauri Sankar Datta, University of Georgia
Composite estimators are very popular for estimation of small area means. Such estimators are obtained by taking a weighted average of a model-based synthetic estimator and a traditional survey estimator or direct estimator. Two important models in small area estimation are the Fay-Herriot model and the nested error regression model. Empirical best linear unbiased prediction (EBLUP) method is widely used in developing suitable composite estimators of small area means based on these models. EBLUP estimator of a small area mean is obtained by replacing the variance parameters in the BLUP estimator of a small area mean. The BLUP estimator is a weighted average of the synthetic estimator and the direct estimator, the weight attached to the latter is proportional to the model error variance. However, often for many data sets the model error variance, and hence the weight to the direct estimator, is estimated to be zero. Consequently, the EBLUP completely ignores the survey regression estimator/direct estimator. Completely ignoring the direct survey estimator is not desirable, especially, if the direct estimator is based on a large small area sample and if the model does not fit adequately.
In this talk, we will consider composite estimators based on weights which are either known or are obtained from other consideration. We will obtain approximate mean squared error of prediction of these estimators. Based on a composite estimator and an estimated measure of uncertainty in estimating a small area mean, we will develop an approximate confidence interval for the small area mean. The resulting confidence interval will be calibrated to achieve the nominal coverage probability to a greater degree of accuracy.
Inference Based on Quadratic-Form Test Statistics Computed from Complex
Survey Data
John Eltinge, Bureau of Labor Statistics
Multivariate analyses of complex survey data are often based on quadratic form test statistics, e.g., 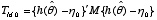 , where
, where 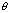 is a
is a 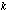 -dimensional parameter vector of interest;
-dimensional parameter vector of interest; 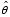 is an estimator that is approximately unbiased for
is an estimator that is approximately unbiased for 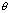 under specified design or model conditions;
under specified design or model conditions; 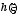 is a smooth function of
is a smooth function of 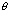 ,
, 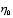 is the value of
is the value of 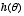 under a particular null hypothesis; and
under a particular null hypothesis; and 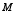 is a symmetric positive definite matrix. In some cases (e.g., customary Wald tests),
is a symmetric positive definite matrix. In some cases (e.g., customary Wald tests), 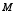 equals the inverse of an estimator of the covariance matrix of the approximate distribution of
equals the inverse of an estimator of the covariance matrix of the approximate distribution of 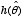 under specified design or model conditions. In other cases (e.g., first- and second-order Rao-Scott adjusted tests), M is based on other approximations related to the covariance structure of
under specified design or model conditions. In other cases (e.g., first- and second-order Rao-Scott adjusted tests), M is based on other approximations related to the covariance structure of 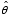 .
.
This paper considers the large-sample properties of inference methods based on 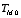 for cases in which the matrix
for cases in which the matrix 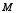 is relatively stable. Three issues receive principal attention.
is relatively stable. Three issues receive principal attention.
- Approximations for the distribution of under a specified null hypothesis, and under moderate deviations from this null hypothesis.
- Use of (a) to evaluate approximate power curves for the tests associated with (a).
- Related efficiency measures computed form the approximate volumes of test-inversion-based confidence sets.
Building on previous literature on misspecification effect matrices, generalized design effects and Rao-Scott-type adjustments, results for (a)-(c) are expressed in terms of the eigenvalues and eigenvectors of the matrix 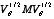 , where
, where 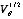 is the symmetric square root of the covariance matrix of the approximate distribution of . The paper closes with illustrations of the general ideas in (a)-(c) for several specific cases, including test statistics based on, respectively, (i) first- and second-order Rao-Scott adjusted tests; (ii) matrices
is the symmetric square root of the covariance matrix of the approximate distribution of . The paper closes with illustrations of the general ideas in (a)-(c) for several specific cases, including test statistics based on, respectively, (i) first- and second-order Rao-Scott adjusted tests; (ii) matrices 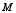 computed from multivariate generalized variance functions; and (iii) matrices computed from stratum collapse or other approximations to the true sample design.
computed from multivariate generalized variance functions; and (iii) matrices computed from stratum collapse or other approximations to the true sample design.
Beginning a Foundation for an Empirical Science of Missing Data in Surveys:
A Review of Contributions by J.N.K. Rao
Robert E. Fay, U.S. Census Bureau
Sample surveys encounter both unit and item nonresponse for a variety of reasons - when the interviewer or organization is unable to contact the respondent, when the respondent refuses, when the respondent is unable to understand a question or recall the information, when the interviewer fails to ask a question or record the answer, or other circumstances. Nonresponse is generally but not exclusively a consequence of human actions, and the study of nonresponse arguably should be largely a social science. A few researchers have begun to make such connections, but this work remains at early stages.
This review will describe a possible future in which survey researchers approach missing data in surveys as a scientific problem, and communicate their results in the standard language of science. The previous, current, and ongoing methodological work of statisticians to develop statistical methods will hopefully be an important part of this emerging science. J.N.K. Rao and his collaborators have made numerous methodological contributions to the statistical analysis of missing data. This review will survey his work and sketch its possible contributions to a future empirical science of missing data in surveys.
Survey Regression Estimation
Wayne A. Fuller and Mingue Park
The basic properties of regression estimators, including variance estimation, are reviewed. The role of models and the construction of design consistent estimators with desirable model properties are discussed. Some practical aspects associated with the construction of regression weights are considered.
Some Issues Arising in the Use of Sampling
in the Legal Setting
Michael D. Sinclair and Joseph L. Gastwirth
Statisticians know that inferences from properly conducted sample surveys are
a reliable and cost-effective method of obtaining information about the population
of interest. Although it took a while before courts accepted samples, today
sample survey evidence is used in cases concerned with trademark infringement,
auditing and accounting to determine the accuracy of tax collections or whether
expenditures were in compliance with a statute and copyright law. Statisticians
using samples based on complex designs may need to demonstrate that these "newer"
methods satisfy legal standards for admissibility. One case where the "experts"
disagree on the reliability of an estimate derived from such a design will be
discussed in depth. A simulation study is described that clarifies the issues
involved. An alternative design, which appears to be more efficient, is proposed
and investigated.
Small Area Estimation Based on NEF-QVF Models and Survey Weights
Malay Ghosh, University of Florida & Tapabrata Maiti, Iowa
State University
The paper proposes small area estimators based on natural exponential family
(NEF) quadratic variance function (QVF) models. Morris (1982,1983) characterized
NEF-QVF distributions and studied many of their properties. We propose pseudo
empirical best linear unbiased estimators of small area means based on these
models when the basic data consist of survey-weighted estimators of these
means, area-specific covariates and certain summary measures involving the
weights. We provide also explicit approximate mean squared errors of these
estimators in the spirit of Prasad and Rao (1990), and these estimators can
be readily evaluated. We illustrate our methodology by estimating the proportion
of poor children in the age group 5-17 for the different counties in one of
the states in the US.
The Trade-off Theory for Sampling and Design.
A. Sam Hedayat, University of Illinois at Chicago
There is an intimate connection between the theory of binary proper block designs and survey sampling without replacement. The theory of trade-off developed originally for block design can be modified and updated so that it can be used for survey sampling. In this talk we shall present the latest news for trade-off theory related to block designs. Then, we shall show their implications and impacts on survey sampling.
Double Sampling: Sampling and Estimation
M.A. Hidiroglou and W. Jocelyn
Business Survey Methods Division, Statistics Canada
The theory of double sampling usually supposes that one large master sample is selected and a sub-sample fully contained in the master sample is taken. Such a sample design is known as two-phase sampling. In this paper, we refer to this sampling method as nested double sampling. The sample of first phase provides auxiliary information (x) at a relatively low cost, whereas the information of interest is collected via the second phase sample. The first-phase data can be used in several ways: (a) to stratify the second phase sample; (b) to improve estimation through regression modelling; (c) to sub-sample a set of non-answering units. Rao (1973) studied double nested sampling in the context of sampling and estimation for a single variable of interest.
It should be noted that it is not necessary that one of the sample be contained in the other or even be selected using the same frame. The case of non-nested double sampling is slightly discussed in classic sampling books such as Des Raj (1968) or Cochran (1977).
Several surveys at Statistics Canada use double sampling. In this article, we present some theory for allocating a sample in this context, as well as the ensuing estimation, given that we have more than one variable of interest. Examples of sample design used at Statistical Canada illustrate the use of this theory.
Mean Squared Error of Empirical Predictor
Jiming Jiang, University of California, Davis
The term empirical predictor refers to a two-stage predictor of a mixed effect, linear or nonlinear. In the first stage, a predictor is obtained but it involves unknown parameters, thus in the second stage, the unknown parameters are replaced by their estimators. In the context of small area estimation, Prasad and Rao (1990) proposed a method based on Taylor series expansion for estimating the mean squared errors (MSE) of empirical best linear unbiased predictor (EBLUP). The method is suitable for a special class of normal mixed linear models. In this talk I consider extensions of Prasad-Rao' approach in two directions. The first extension is to estimation of MSE of EBLUP in general mixed linear models, including mixed ANOVA models and longitudinal models. The second extension is to estimation of MSE of empirical best predictor in generalized linear mixed models for small area estimation.
This talk is based on joint work with Kalyan Das, Partha Lahiri and J.N.K. Rao.
Methods for Variance Estimation in Surveys with Imputed Data
Graham Kalton, J. Michael Brick, and Jae Kwang Kim
The standard methods for estimating the variances of survey estimates based on complex sample designs employ either a Taylor Series approximation or some form of replication, such as balanced repeated replication or jackknife repeated replication. However, these methods underestimate the true variance of a survey estimate when some of the data used in the estimate are imputed. Several different methods have been developed to overcome this problem, including adjusted jackknife replication methods, a fractional imputation method, model-assisted methods, and multiple imputation. This paper deals mainly with variance estimation when missing values have been imputed using some form of hot deck imputation. It reviews the various variance estimation methods with a focus on the missing data models underlying the methods.
Clarifying Some Issues in the Analysis of Survey Data
Phil Kott, USDA/NASS/RDD
The literature offers two distinct reasons for incorporating sample weights into the estimation of linear regression coefficients from a model-based point of view. Either the sample design is informative or the model is incomplete. The traditional sample-weighted least-squares estimator can be improved upon even when the sample design is informative, but not when the standard linear model fails and needs to be extended.
It is often assumed that the realized sample derives from a two-phase process. In the first phase, the finite population is drawn from a hypothetical superpopulation via simple random (cluster) sampling. In the second phase, the actual sample is drawn from the finite population. Many think that the standard practice of treating the sample as if it was drawn with replacement from the finite population is (roughly) equivalent to the full two-phase process. That is not always the case.
Bias in the Epidemiological Indicators of Risk due to
Record Linkage Errors in Cohort Mortality Studies
R. Mallick, Carleton University
D. Krewski, University of Ottawa
J.M. Zielinski, Health Canada
The advent of computerized record linkage methodology has facilitated the conduct of cohort mortality studies in which exposure data in one database are electronically linked with mortality data from another database. Epidemiological indicators of risk such as standardized mortality ratios or relative risk regression model parameters can be subject to bias and additional variability in the presence of linkage errors. In this paper, we review recent analytical results on bias and additional variations in standardized mortality ratios and logistic regression model parameters in large samples due to linkage errors. A simulation study based on data from the National Dose Registry of Canada is then used to examine bias and variation in these indicators in small samples.
Estimation of Mean Wages for Small-areas: an EBLUP Approach
M. Sverchkov, U.S. Bureau of Labor Statistics and User Technology Associates, Inc.
P. Lahiri, University of Nebraska, Lincoln and University of Maryland at College Park
We use data from the National Compensation Survey conducted by the U.S. Bureau of Labor Statistics to estimate mean wages for many cells obtained by classifying industries and geographic regions. The direct survey estimator of mean wage for a particular cell is typically unreliable because of small sample size in the cell. In order to improve on the direct survey estimator, we consider a three-level hierarchical model which connects the cells and use an empirical best linear unbiased prediction (EBLUP) method to estimate the mean wages for the cells. Based on a test that we developed, it turns out that the sampling weights can be ignored for our estimation purposes. A jackknife method is used to estimate the MSE of our proposed EBLUP.
Theoretical Foundations of the Generalised Weight Share Method
Pierre Lavallée, Statistics Canada and Jean-Claude Deville
To select the samples needed for social or economic surveys, it is useful to have sampling frames, i.e. lists of units intended to provide a way to reach desired target populations. Unfortunately, it happens that one does not have a list containing the desired collection units, but rather another list of units linked in a certain way to the list of collection units. One can speak therefore of two populations UA and UB linked to each other, where one wants to produce an estimate for UB. Unfortunately, a sampling frame is only available for UA. It can then be considered to select a sample sA from UA in order to produce an estimate for UB by using the correspondence existing between the two populations. This can be designated by indirect sampling.
Estimation for a target population UB surveyed by indirect sampling can constitute a big challenge, in particular if the links between the units of the two populations are not one-to-one. The problem comes especially from the difficulty to associate a selection probability, or an estimation weight, to the surveyed units of the target population. In order to solve this type of estimation problem, the Generalised Weight Share Method (GWSM) has been developed by Lavallée (1995) and Lavallée (2001). The GWSM provides an estimation weight for every surveyed unit of the target population UB. Basically, this estimation weight corresponds to a weighted average of the survey weights of the units of the sample sA.
The GWSM possesses certain desirable properties, such as unbiasedness for totals. Under mild conditions, unbiasedness is kept whatever the linkage existing between the populations UA and UB. This affects however the precision of the estimates produced by the GWSM.
The purpose of this paper is to describe the theoretical foundations underlying the GWSM. This will enable us to explain, for example, the unbiasedness of the method and what types of linkage produce the best precision. First, we will give an overview of the GWSM as it has been described in Lavallée (1995) and Lavallée (2001). Second, we will reformulate the GWSM in a more theoretical framework that will use, for instance, matrix notation. The use of matrix notation for the GWSM has previously been presented by Deville (1998). Third, we will use this theoretical framework to state some general properties associated to the GWSM. For example, we will study the effect of various typical matrices of links between UA and UB on the precision of the estimates obtained from the GWSM. Another example is the study of the effect of these typical matrices of links on the transitivity of the GWSM. Transitivity is to go from the population UA to the target population UB, through an intermediate population UC.
Survival Analysis Based on Survey Data
Jerry Lawless, University of Waterloo
As longitudinal surveys in which panels of individuals are followed over a period of months or years have become common, so has the use of survival analysis methodology with survey data. This talk will review issues associated with analytic inference for survival or duration times when the data arise from a complex survey. Methodology for parametric and for semiparametric models will be described. Examples will be drawn from Canadian and U.S. national longitudinal surveys.
Estimation Problems in Multiple Frame Surveys
Sharon Lohr, Arizona State University
In a multiple frame survey, independent probability samples are taken from each of several sampling frames that together cover a target population. Multiple frame surveys can achieve
the same accuracy as a single frame survey, but with much lower costs. In this talk, we discuss some of Professor Rao's contributions in multiple frame survey theory and practice. We also (in joint work with Professor Rao) examine extensions of the Skinner/Rao (1996) pseudo-maximum-likelihood estimator to more than two frames.
A Comparison of Data Augmentation Algorithms for Small Area Empirical Bayes Estimation of Exponential Family Parameters in Hierarchical Generalized Linear Models with Random Effects
Patrick J. Farrell, Carleton University,
Brenda MacGibbon, Université du Québec à Montréal,
Thomas J. Tomberlin, Concordia University
The basic idea for the small area estimation problem studied here consists of incorporating into a generalized linear model nested random effects which reflect the complex structure of the data in a multistage sample design. However, as compared to the ordinary linear regression model, it is not feasible to obtain a closed form expression for the posterior distribution of the parameters. The approximation most used to avoid the intractable numerical integration is that originally
proposed by Laird (1978). This method, which uses the EM algorithm, has been used previously for logistic regression with random intercepts by Stiratelli, Laird and Ware (1984) and for small area estimation of proportions by Dempster and Tomberlin (1980), MacGibbon and Tomberlin (1989), Farrell, MacGibbon and Tomberlin (1994, 1997a, 1997b). Essentially, the posterior is expressed as a multivariate normal distribution having its mean at the estimated mode and covariance matrix equal to the inverse of the information matrix evaluated at this mode. Here, inspired by the work of Gu and Li (1998) on stochastic approximation computing techniques, we also study a stochastic simulation method to approximate this posterior first by assuming normality and secondly in a more general approximation by a rejection/acceptance sampling method. The results from these three methods are compared in a Monte Carlo study on simulated data from a two-stage sample design. A real data set is also presented.
Pseudo-Coordinated Bootstrap Method for Inference from Two Overlapping Sample Surveys
Harold Mantel and Owen Phillips, Statistics Canada
This paper deals with the problem of variance estimation for the difference of two cross-sectional estimates from different points in time based on partially overlapping samples. This situation may arise, for example, in the context of a rotating panel survey, or when a longitudinal panel of persons is supplemented by cohabitants or by extra sample for cross-sectional estimation. The partial overlap of the samples induces correlation in the cross-sectional estimates that must be accounted for in the variance estimation procedures. One approach to this problem is to use a coordinated bootstrap method where, for clusters that are common to the two cross-sectional samples by design, the same bootstrap subsamples of clusters are used for each time point. Roberts, Kovacevic, Mantel and Phillips (2001) proposed a pseudo-coordinated bootstrap method that can be used when cross-sectional bootstrap weights were produced independently for each of the two time points. In this paper we propose variations and refinements of the pseudo-coordinated bootstrap method, and compare them numerically using data from Statistics Canada’s Survey of Labour and Income Dynamics.
Mean Square Error Evaluation in Small
Area Estimation using Parametric Bootstrap
Danny Pfeffermann, Hebrew University and University
of Southampton
One of Rao’s outstanding contributions to survey
sampling theory is his pioneering work with N. Prasad on MSE evaluations in
Small Area Estimation. This work produced very simple estimators for the prediction
MSE of the Empirical Best Linear Unbiased Predictors (EBLUP) under three models
in common use. It paved the way of obtaining similar estimators for other models
and prompted the development of other procedures for the evaluation of the prediction
MSE of the EBLUP and Empirical Bayes predictors.
In this paper I shall discuss the use of a parametric bootstrap method for the
evaluation of the prediction MSE of the EBLUP. The method is very general and
consists of generating a large number of bootstrap samples from the model fitted
to the original observations, re-estimating the model parameters for each of
the samples and modifying the empirical MSE calculated from the bootstrap samples
to obtain MSE estimators of desired order. The performance of the method will
be illustrated and compared to the estimators proposed by Prasad and Rao under
two different models using simulations.
Resampling Methods for Mixed Models
with Special Application
to Small Area Estimation.
N.G.N. Prasad, University of Alberta
In this talk I will first consider both jackknife and bootstrap methods
for a general mixed unbalanced model 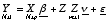 where
where 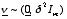 and
and 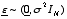 with the objective of obtaining robust inference for functions of variance components,
with the objective of obtaining robust inference for functions of variance components,
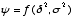 . The performance of these methods will
also be considered in the context of mean square estimation of small area means.
. The performance of these methods will
also be considered in the context of mean square estimation of small area means.
Statistical Inferences in the Presence
of Human Behavior
Lakshmi Damaraju, Centocor and Damaraju Raghavarao,
Temple University
When subjective responses are collected from the respondents, a small
fraction of respondents give higher or lower values. These fractions differ
from population to population. When the collected data are analyzed at a nominal
level of 0.05, the actual level will be different from 0.05. We will examine
the level and power of some of the commonly used tests in this presentation.
Mammographic CAD Using Bootstrap Ensembles
J. Sunil Rao and Mireya Diaz, Case Western Reserve University
We present a method for recognizing suspicious masses in digital
mammograms. Mammography is an effective tool for the early detection of possibly
irregular breast masses. Computer-aided diagnosis (CAD) using digital mammograms
can be a very effective complement to a visual
diagnosis.
Our approach classifies each pixel indirectly into mass or non-mass via one-split
classification stump derived from a broken line regression model using the pixel
intensity profile with respect to a given origin. A bootstrap aggregation method
(bagging) combining multiple versions of these simple circle approximations
can be an effective method for detecting more
complex shapes.
Two data resampling schemes are implemented: resampling broken line residuals
and resampling candidate pixel centers. Both approaches were tested on simulated
"masses" of circular and elliptical shapes under different noise conditions.
Results follow the theory, with bootstrapping
residuals having a beneficial effect for generally circular masses, and bootstrapping
centers providing large decreases in misclassification error for more general
shapes.
Among the major advantages of the method are its simplicity, adaptability and
lack of need for supervised training.
Small Area Estimation
Poduri S.R.S. Rao
The BLUP and the corresponding estimators for the means and totals
of small areas are considered. The MIVQUE, REML and related procedures are suggested
for the estimators and their MSEs.
Some Extensions of Prasad and Rao's
Mean Squared Error Estimator
for Small Areas
Louis-Paul Rivest, Université Laval
Prasad and Rao (1990) derived an estimator for the mean squared error
of empirical Bayes small area estimates that accounts for the estimation of
the parameters of the smoothing model. This talk presents an alternative approach
to this construction for area level models. It uses the conditional mean squared
error estimator of Rivest and Belmonte (2000). This new approach allows the
derivation of a correction term for the estimation of the small area variances.
Also, when these small area variances are known and equal, an unbiased minimum
variance mean squared error estimator is obtained. The calculations make extensive
use of Stein's lemma for
the expectation of normal random variables.
Maximum Likelihood for Stratified
Cluster Sampling
with Informative Stratification
Alastair Scott, University of Auckland
We look at fitting regression models to data from stratified cluster
samples when the strata are based on the observed responses within clusters.
Family studies in genetic epidemiology, where the probability of selecting a
family into the study depends on the incidence of disease within the family,
form an important class of examples. Full maximum likelihood involves modelling
the population distribution of the covariates which is simply not feasible when
there are a large number of potential covariates. Instead we develop efficient
semiparametric methods in which
the covariate distribution is left completely unspecified. We compare these
new methods with the standard survey approach using weighted estimating equations
and with other approaches that have been suggested recently.
Review and Evaluation of Bayesian
Diagnostic Methods for Hierarchical Models
J. Sedransk, Case Western Reserve University and Guofen
Yan, Cleveland Clinic Foundation
We describe Bayesian diagnostic methods with an emphasis on detecting
incorrect specification of the variance structure of a linear model. Then we
evaluate the performance of several techniques when the fitted model does not
have the hierarchical structure present in the observed data. The methods to
be presented are:
(a) summary of standardized predictive residuals,
(b) distribution of the set of individual posterior predictive p values,
- posterior predictive p values using checking functions that summarize
important features of the underlying structure, and
- partial predictive p values, analogous to the p
values in (c).
Hypothesis Testing in Two-way Contingency
Tables under Hot Deck Imputation
Jun Shao and Hansheng Wang, University of Wisconsin-Madison
Two-way contingency tables are widely used for the summarization of
a simple random sample of two categorical variables. We consider tests for the
independence of the two categorical variables and other goodness of fit tests
in the situation where the two-dimensional categorical data have nonrespondents
imputed by using a conditional hot deck imputation method or a marginal hot
deck imputation method. Under marginal hot deck imputation, we show that the
usual chi-square test for independence is still asymptotically valid if the
imputed values are treated as observed data. Under conditional hot deck imputation,
we show that the limiting distribution of the usual chi-square test is proportional
to a chi-square distribution so that multiplying a simple correction factor
leads to an asymptotically valid test procedure. For testing goodness of fit,
a Wald type test and a Rao-Scott type corrected chi-square test are derived.
Some simulation results are presented.
Estimating Function Based Approach
for Hierarchical Bayes
Small Area Estimation with Survey Data
A.C. Singh, R.E. Folsom, Jr., and A.K. Vaish (RTI International)
In estimating parameters of a model assumed to govern the finite population,
it is often the case that the sampling design cannot be ignored. A natural way
to overcome the presence of nonignorable sample designs in the joint design-model
based estimation is to work with transformed or aggregate-level data such as
the direct survey estimates for small areas. Such an approach was used in Fay-Herriot’s
(1979) pioneering paper on small area estimation. However, the FH approach does
have some limitations: (i) the large sample assumption required to validate
the Gaussian approximation is not reasonable for direct small area estimates;
(ii) smoothing of estimates of variances of direct estimates may not be adequate
or possible for areas with few or no observations; (iii) unit-level covariate
information cannot be exploited; and (iv) models become internally inconsistent
when the level of aggregation is changed. In this paper a new approach representing
a unit-level generalization of FH is presented which, like FH, employs data
aggregation but through survey-weighted estimating functions rather than estimators.
Working with estimating functions (EFs) helps to alleviate the problems associated
with FH. For hierarchical Bayes (HB) small area estimation, the proposed approach
simply replaces the likelihood (computed under the assumption of ignorable design)
with the estimating function based Gaussian likelihood, which does not require
ignorability of the design. The method is illustrated by means of a simple example
of fitting a HB linear mixed model to data obtained from a non-ignorable sample
design. Both fixed and random parameters are estimated to construct small area
estimates. Different scenarios for non-ignorability are considered. MCMC is
used for HB parameter estimation.
Variance Estimation for a Regression
Composite Estimator
in a Rotating Panel Survey
M.P. Singh, J.G. Gambino, R. Boyer and E. Chen
In January 2000, the Canadian Labour Force Survey (LFS) started using
a regression composite estimator (RCE) to produce monthly estimates. This estimator
takes advantage of the correlations over time induced by sample overlap to achieve
gains in efficiency. A variance estimation system for the RCE only became ready
for production use in 2002. The development of a computationally efficient variance
estimation system was a major challenge. This system is also being used to study
possible modifications to the estimation method itself. In this paper, we describe
the RCE, the variance estimation system and the results of a study conducted
to examine the effects of different choices of weight attached to estimation
of level and change in the RCE.
Imputation for Measurement Error in the Estimation
of the Distribution
of Hourly Pay
C. Skinner, University of Southampton
Two measures of hourly pay are available from the U.K. Labour Force
Survey. One is available for almost all employees in the sample, but is subject
to measurement error. The other is much more accurate, but is only available
for a subsample. The use of imputation in the estimation of the distribution
of hourly pay will be discussed. The choice of imputation method and variance
estimation for the resulting distribution estimates will be considered.
Evaluation of Weighting Adjustments Methods for
Partial Nonresponse Bias
Phil Smith, Centers for Disease Control and Prevention
Many health surveys conduct an initial household interview to obtain
demographic information and then request permission to obtain detailed information
on health outcomes from the respondent's health care providers. A "complete
response" results when both the demographic information and the detailed
health outcome data are obtained. A "partial nonresponse" results
when the initial interview is complete but, for one reason or another, the detailed
health outcome information is not obtained. If "complete responders"
differ from "partial nonresponders" and the proportion of partial
nonresponders in the sample is at least moderately large, statistics that use
only data from complete responders may be severely biased. In health surveys
it is customary to adjust survey estimates to account for these differences
by employing a "weighting class" adjustment. Even after making these
adjustments, an important question to ask is, "How well does the method
work to reduce partial nonresponse bias?" This paper describes an approach
for evaluating how well weighting class adjustments work. Data from the National
Immunization Survey are used to illustrate the approach by evaluating two methods
for constructing of weighting classes.
Post-stratification Revisited
T.M.F.Smith, University of Southampton and R.A.Sugden, Goldsmiths
College, London
In Sugden and Smith (2002) we investigated the conditions under which
exact linear unbiased estimators of linear estimands, and also exact quadratic
estimators of quadratic estimands, could be constructed. Inter alia we provided
an alternative proof of Jon Rao’s famous result (Rao (1979)) on non-negative
unbiased estimators of mean square errors. In this paper the approach is applied
to post-stratified estimators of finite population means and totals. The resulting
estimators generalise those in Doss et al (1979). Some properties of these estimators
are explored.
Allocation to Strata in Surveys that
Screen for Eligible Populations
K.P. Srinath, Abt Associates Inc
In many telephone surveys, the sample from an eligible population
is selected through screening a larger sample from a general population. For
example, if we want to select a sample of households with children, a larger
sample of households is first screened to identify and select such households.
The size of the sample that is required for screening depends on the desired
sample size from the eligible population and the proportion of the eligible
population in the general population. This proportion is generally called the
eligibility rate. If the effort and cost of screening are high, then it is desirable
to minimize the required screening sample size. If the general population is
divided into strata and the eligibility rates vary widely among strata, then
it is possible to look at sample allocations, which minimize the size of the
screening sample without too much loss in the precision of the estimates relating
to the eligible population. We examine such allocations and provide examples.
We also look at sample allocations when there is a need to oversample from certain
subpopulations or domains of the eligible population. We present some simple
allocation methods to achieve a predetermined number of sampling units belonging
to a domain when strata have widely varying proportions of subpopulations.
Singular Wishart and Multivariate
Beta Distributions
M.S. Srivastava, University of Toronto
In this paper, we consider the case when the number of observations
n is less than the dimension p of the random vectors which are
assumed to be independent and identically distributed as normal with non singular
covariance matrix. The central and noncentral distributions of the singular
Wishart matrix S = XX’ , where X is the p _ n matrix
of observations are derived with respect to Lebesgue measure. Properties of
this distribution are given. When the covariance matrix is singular, pseudo
singular Wishart distribution is also derived. The result is extended to any
distribution of the type f (XX ’) for the central case. Multivariate
beta distributions with respect to Lebesgue measure are also given.
Quasi-likelihood Inference in Linear Models for
Asymmetric
Longitudinal Data
Brajendra C. Sutradhar and Atanu Biswas
Memorial University of Newfoundland and Indian Statistical Institute
It is well-known that the generalised least square (GLS) estimators
are consistent as well as efficient for the regression parameters in normal
linear models with cluster correlated errors, where the correlations arise because
of the repetition of the individual responses over time. Obtaining consistent
and efficient estimators for the regression parameters in the linear model with
asymmetrical and longitudinally correlated errors is, however, proven to be
difficult. This is mainly because of the difficulty in modelling the longitudinal
correlation structure for the asymmetric data. In this paper, analogous to the
normality based auto-correlation structure, we first develop an auto-association
structure for the repeated asymmetric data. This association structure is then
used to develop a quasi-likelihood estimating equation for the regression parameters
of the model. The resulting estimators are shown to be consistent and efficient.
The performance of the proposed quasi-likelihood approach will be examined through
a simulation study. A numerical example will also be considered.
Applications of Rao-Scott Chi-Squared
Tests in Marketing Research
D. Roland Thomas and Yves J. Decady
The aim of this talk is to provide another illustration of the wide
range of application of Rao and Scott's (1981, JASA; 1984, Annals of Statistics)
corrected chi-squared statistics. Originally designed to extend standard categorical
data testing procedures to data from complex multi-stage surveys, these techniques
have already found wide application in the analysis of experimental data in
bio-statistics and other disciplines. The application described in this paper
relates to multiple response data (MRD), obtained when a list of items is presented
in a survey question and respondents are asked to select all items that apply
to them. It will be assumed that the surveys in question are simple random,
though extensions to complex surveys can be made. MRD are encountered in many
disciplines, including the health and social sciences and are particularly popular
in marketing research. Analysis is usually restricted to tabular summaries and
percentages, though more complex descriptive techniques such as multi-dimensional
scaling and correspondence analysis are sometimes used. However, many marketing
and other researchers avoid using MRD because of the difficulty of testing hypothesis
such as goodness of fit and independence on tables that feature multiple response
data. Recently, there has been a surge of interest in developing test procedures
for use with MRD, starting with Umesh's (1995; Journal of Forecasting) proposed
"pseudo chi-squared tests", which lacked a corresponding reference
distribution. Since then, tests of association for MRD have been developed based
on bootstrapping and on a variety of other modelling techniques of varying degrees
of complexity. Decady and Thomas (2000, Biometrics), on the other hand, showed
that very simple-to-apply tests could be developed by using Rao-Scott methods
to develop first-order corrections to statistics of the pseudo chi-squared type.
This approach has since been used by Bilder, Loughin and Nettleton (2000; Communications
in Statistics) and Thomas and Decady (2000, SSC Proceedings), to justify an
alternative first-order chi-squared procedure proposed by Agesti and Liu (1999;
Biometrics) that is even easier to apply. Recent work will be reviewed and further
MRD applications of the Rao-Scott approach will be described in the paper, including
tests of equality of item selection probabilities and tests of marginal independence
featuring two multiple response variables. Second-order Rao-Scott corrections
for MRD tests will be described and shown to provide good test properties even
in extreme situations. The Rao-Scott procedures will be illustrated on some
marketing research data, along with extensions of the tests to take account
of aggregation of multiple response categories. Applications to MRD gathered
in complex surveys will be also be briefly discussed.
The Use of Run Length to Model Longitudinal
Binary Data with Misclassification
M. E. Thompson, University of Waterloo
K. Shum, Capital One, Toronto
R. J. Rosychuk, University of Alberta
This paper considers the application of sampled Markov and alternating
renewal process models to longitudinal binary data, along with a simple model
for misclassification with independent errors. Maximum likelihood estimation
is very sensitive to model misspecification. Assuming equilibrium and fitting
transition pair or transition triplet counts provides estimability only in certain
directions in the parameter space. The use of run length distributions for fitting
provides a larger number of degrees of freedom for estimation, and has the advantage
of tying estimation more directly to the sojourn times in the states. The method
is developed and applied to a moderate sized clinical trials data set. Adaptation
of the method to data from larger scale studies and surveys is outlined.
A System of Experimental Design
C.F.J. Wu
A system of experimental design is outlined that attempts to encompass
many of the major work in factorial experimental design of the 20th century.
The system has four broad branches: (i) regular orthogonal designs, (ii) nonregular
orthogonal designs, (iii) response surface designs, (iv) optimal designs. Regular
orthogonal designs include the 2n-k and 3n-k designs.
Major issues are optimal assignment of factors and interactions via the minimum
aberration and related criteria. The problem becomes harder if the factors cannot
be treated symmetrically (e.g., blocking or split-plot structure, and robust
parameter designs.) Nonregular orthogonal designs were traditionally used for
factor screening and main effect estimation. They have been shown to possess
some hidden projection property that allows interactions among a smaller number
of factors to be estimated. Response surface designs are used primarily for
exploring parametric surfaces, while optimal designs are chosen to optimize
a given criterion based on a specified model. Recent work shows that many nonregular
designs can be used to screen a large number of factors as well as efficiently
estimate a quadratic response surface on projected designs. This shows that
the boundary between (ii) and (iii) is getting blurred.
Model-Based Design Consistent Small
Area Estimation
with Automatic Benchmarking
Yong You, Statistics Canada and J.N.K. Rao, Carleton
University
Unit level random effects models including nested error linear regression
models have been used in small area estimation to obtain efficient model-based
estimators of small area means. Such estimators typically do not make use of
the survey weights. As a result, the estimators are not design consistent unless
the sampling design is self-weighting within areas. In this paper, a survey-weighted
modelling approach is developed by combining the survey weights and the nested
error linear regression models under empirical best linear unbiased prediction
(EBLUP) and hierarchical Bayes (HB) frameworks. For the EBLUP approach, a pseudo-EBLUP
estimator and its corresponding mean squared error (MSE) are obtained. For the
HB approach, a pseudo-posterior mean and pseudo-posterior variance of the small
area mean are obtained. The proposed pseudo-EBLUP and pseudo-HB estimators are
design consistent and has a nice automatic benchmarking property without any
post-adjustment. The proposed estimators are evaluated using a real data set
studied by Battese, Harter and Fuller (1988).
A Unified Approach to Variance Estimation
for Complex Surveys
Wesley Yung, Statistics Canada
Parameters of interest such as population means, ratios and regression
coefficients from linear or logistic regressions can be expressed as solutions
to suitable population "estimating equations". Estimates of these
parameters can be obtained by solving sample estimating equations which involve
design weights as well as adjustments due to auxiliary information and/or nonresponse
weight adjustments. Using the jackknife linearization approach, we obtain standard
errors of parameter estimates obtained from the estimating equations approach.
These standard errors incorporate estimation weights resulting from the use
of auxiliary data during estimation. We show how the estimating equations approach
can be implemented to obtain a unified and flexible computer system to calculate
estimates and their associated standard errors.
Using Administrative Records to Improve
Small Area
Estimation: An Example from the U.S. Decennial Census
E. Zanutto, University of Pennsylvania
We present a small area estimation strategy that combines two related
information sources: census data and administrative records. Our methodology
takes advantage of administrative records to help impute small area detail while
constraining aggregate-level estimates to agree with unbiased survey estimates,
without requiring the administrative records to be a perfect substitute for
the missing survey information. We illustrate our method with data from the
1995 U.S. Decennial Test Census, in which nonresponse follow-up was conducted
in only a sample of blocks, making small area estimation necessary. To produce
a microdata file that may be used for a variety of analyses, we propose to treat
the unsampled portion of the population as missing data and impute to complete
the database. To do so, we estimate the number of nonrespondent households of
each "type" (represented by a cross-classification of cateogorical
variables) to be imputed in each small area. Donor households for these imputations
can be chosen from the sampled nonresponse followup sample, the respondent households,
or the administrative records households (if they are of sufficient quality).
We show, through simulation, that our imputation method reduces the mean squared
error for some small area (block-level) estimates compared to alternative methods.
Evaluating Qualitative Assays in Sensitivity
and Specificity
Bob Zhong, Abbott Laboratories
Sensitivity and specificity are two important indices of performance
of qualitative assays. The evaluation of these indices usually requires one
to identify the true disease state of all subjects involved in a study. That
means a perfect test, or gold standard, is needed and can be applied to all
subjects. However, sometimes a gold standard testing method may not be used
on all patients because of high cost or adverse effect on subjects' welfare.
A widely used design is to apply a traditionally used assay and the new assay
under investigation to the same specimen, and to apply the gold standard test
only to subjects with discordant test results. This design has been criticized
by many and in fact, the statistics based on this design usually over-estimate
sensitivity and specificity. In this paper I propose two new designs and methods
to estimate sensitivity and specificity. Simulation results show that the proposed
methods perform better than the commonly used existing methods.
To evaluate qualitative assays related to blood specimens, studies for storage
conditions, interfering substances, etc., are performed to establish equivalency
of the assay under standard and various other conditions. For example, blood
is usually collected in a tube and shipped to a central laboratory for testing.
During the shipping process, temperature and time from collection to testing
may vary. Are the testing results after shipping the same as the ones as measured
immediately after collection? In these studies, blood donor specimens (after
they are verified negative) are used as a sample from a negative population
and blood donor specimens with spiked analyte are used as a sample from a positive
population. The equivalent criterion is usually specified as no qualitative
change for specimens under testing conditions. Currently, the target spiking
ranges and sample sizes are decided subjectively. I propose new acceptance criteria
for the evaluation of an assay under various conditions. New ideas about how
to select the target spiking range and to specify the sample size accordingly
are also presented.
[go to top]
Go to ICRASS Preliminary Program